
Cela faisait longtemps que je n’avais pas écrit un article sur les fonctionnalités du langage JavaScript. Le dernier remonte à 2021 (outch, ça commence à dater !) et portait sur les itérateurs et les générateurs. Eh bien, ça tombe à pic, car les iterator helpers viennent tout juste de passer au stade 4 du processus de standardisation en octobre 2024, ce qui signifie qu’ils font officiellement partie de la norme ECMAScript !
Bref rappel sur les itérateurs et les générateurs
Avant de plonger dans les iterator helpers, revenons rapidement sur ce que sont un itérateur et un générateur. Ces concepts sont essentiels pour bien comprendre comment fonctionnent les helpers ! Pour plus de détails, je vous invite à consulter mon article précédent, qui se penche en profondeur sur les itérateurs et les générateurs en JavaScript.
Qu’est ce qu’un itérateur ?
Un itérateur ou iterator est un objet qui permet de parcourir une collection d’éléments séquentiellement, comme un tableau ou une chaîne de caractères, ou même de générer des valeurs dynamiques à la demande, comme une suite de nombres.
Chaque itérateur possède une méthode next qui, à chaque appel, renvoie un objet contenant :
value: la valeur courante de la séquence,done: un booléen indiquant si l’itération est terminée (true) ou non (false).
Pour qu’un objet soit itérable, il doit inclure une méthode spéciale, Symbol.iterator, qui retourne un itérateur. Grâce à cette méthode, JavaScript reconnaît l’objet comme itérable, ce qui permet de l’utiliser dans des boucles comme for...of ou avec le spread operator (...).
Exemples d’itérateurs
const arr = [10, 20, 30];const iterator = arr[Symbol.iterator]();
console.log(iterator.next()); // { value: 10, done: false }console.log(iterator.next()); // { value: 20, done: false }console.log(iterator.next()); // { value: 30, done: false }console.log(iterator.next()); // { value: undefined, done: true }Ici, le tableau arr possède déjà la méthode Symbol.iterator, ce qui permet de créer un itérateur en appelant arr[Symbol.iterator](). Chaque appel de next avance dans le tableau, jusqu’à ce que done soit égal à true et signale la fin de l’itération.
Vous pouvez aussi utiliser directement for...of pour parcourir le tableau sans créer d’itérateur explicitement :
for (const value of arr) { console.log(value); // Affiche 10, 20, 30}Les itérateurs ne se limitent pas aux collections fixes comme les tableaux, ils peuvent également produire des séquences dynamiques ou même infinies. Cela permet de générer des valeurs à la demande, sans avoir besoin de les stocker en mémoire. Voici un exemple d’itérateur infini qui génère des nombres séquentiels :
const infiniteNumbers = { current: 0, next() { return { value: this.current++, done: false }; }};
console.log(infiniteNumbers.next()); // { value: 0, done: false }console.log(infiniteNumbers.next()); // { value: 1, done: false }console.log(infiniteNumbers.next()); // { value: 2, done: false }Dans cet exemple, chaque appel à next génère un nombre de manière continue, sans fin. Comme done reste toujours false, l’itérateur peut produire des valeurs sans s’arrêter.
Qu’est ce qu’un génerateur ?
Un générateur, ou generator, ou encore fonction génératrice, est une fonction spéciale qui peut produire plusieurs valeurs au fil du temps, avec la particularité de pouvoir suspendre son exécution et la reprendre plus tard. Contrairement aux fonctions classiques, qui exécutent tout leur code d’une traite, un générateur peut s’interrompre à tout moment et reprendre exactement là où il s’était arrêté.
Il existe plusieurs cas d’utilisation pour les générateurs, que je vous invite à découvrir dans mon précédent article, mais celui qui nous intéresse ici est leur capacité à créer des itérateurs.
Les générateurs se définissent avec function* et utilisent l’instruction yield pour produire chaque valeur. Lorsqu’on appelle un générateur, il ne s’exécute pas immédiatement. Au lieu de cela, il retourne un itérateur que l’on peut contrôler avec la méthode next.
Comment fonctionne un générateur ?
Chaque appel à next sur l’itérateur exécute le générateur jusqu’au prochain yield, où il produit une valeur, puis se met en pause. À la fin du générateur, done devient true, indiquant que toutes les valeurs ont été produites.
Exemples de générateurs
function* simpleGenerator() { yield 'A'; yield 'B'; yield 'C';}
const generator = simpleGenerator();
console.log(generator.next()); // { value: 'A', done: false }console.log(generator.next()); // { value: 'B', done: false }console.log(generator.next()); // { value: 'C', done: false }console.log(generator.next()); // { value: undefined, done: true }Dans cet exemple, chaque yield permet de produire une valeur, et chaque appel de next reprend là où le générateur s’était arrêté, jusqu’à ce que done soit true.
Les générateurs sont aussi utiles pour des séquences calculées au fil du temps. Par exemple, pour générer la suite de Fibonacci :
function* fibonacci() { let [a, b] = [0, 1]; while (true) { yield a; [a, b] = [b, a + b]; }}
const fib = fibonacci();console.log(fib.next().value); // 0console.log(fib.next().value); // 1console.log(fib.next().value); // 1console.log(fib.next().value); // 2console.log(fib.next().value); // 3Présentation des iterator helpers
Les iterator helpers apportent un ensemble de méthodes pratiques pour la manipulation des itérateurs en JavaScript. Ils permettent de manipuler des séquences d’éléments, le tout sans avoir à créer des structures intermédiaires en mémoire. Ces méthodes sont donc particulièrement efficaces pour travailler avec des séquences volumineuses ou infinies.
Voici un aperçu des principaux iterator helpers et de leur utilité :
-
filter(callback): Crée une sous-séquence en ne conservant que les éléments qui répondent à une condition spécifiée. -
map(callback): Applique une transformation à chaque élément de la séquence, générant une nouvelle séquence contenant les valeurs modifiées. -
take(n): Récupère lesnpremiers éléments de la séquence. -
drop(n): Ignore lesnpremiers éléments de la séquence. -
reduce(callback, initialValue): Combine les valeurs d’une séquence pour obtenir une valeur finale unique, en appliquant une fonction d’agrégation. -
forEach(callback): Exécute une fonction pour chaque élément de la séquence, sans renvoyer de nouvelle séquence. -
some(callback): Renvoietruesi au moins un élément de la séquence satisfait la condition spécifiée, sinonfalse. -
every(callback): Renvoietrueuniquement si tous les éléments de la séquence satisfont la condition donnée, sinonfalse. -
find(callback): Renvoie le premier élément de la séquence qui répond à la condition danscallback, ouundefineds’il n’y en a aucun. -
flatMap(callback): Applique une transformation à chaque élément, tout en “aplatissant” les sous-séquences résultantes. -
toArray(): Convertit un itérateur en tableau, forçant ainsi l’évaluation complète de la séquence en mémoire.
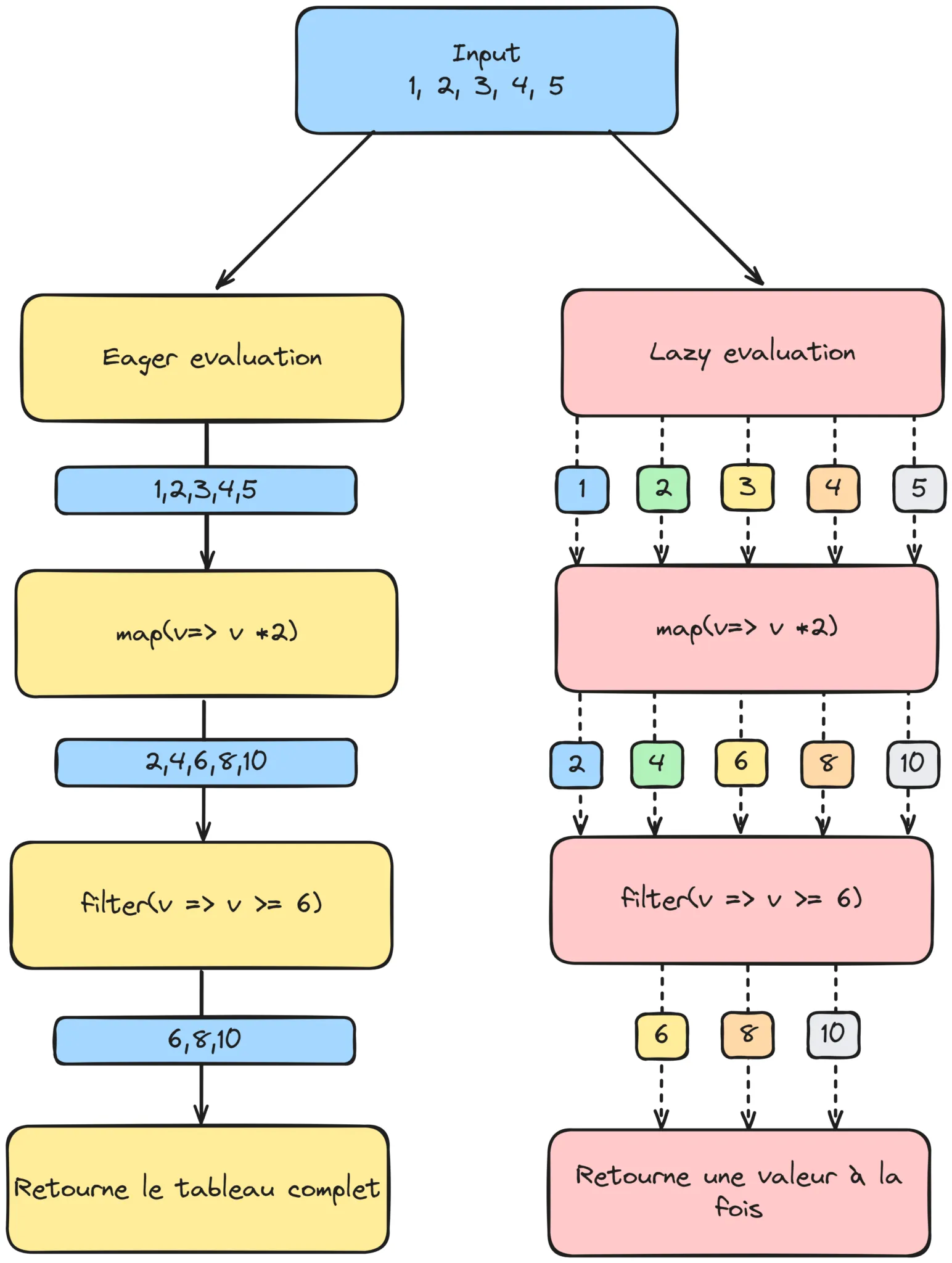
Avec ces iterator helpers, on peut enchaîner facilement des opérations complexes sur des séquences sans créer de copies intermédiaires et sans surcharger la mémoire. Cette approche, qui repose sur l’évaluation paresseuse (lazy evaluation), est idéale pour travailler avec des flux de données en continu ou des séquences infinies tout en conservant les ressources.
Évaluation paresseuse (lazy evaluation) vs évaluation immédiate (eager evaluation)
Avant de présenter les iterator helpers, il est essentiel de comprendre deux approches de traitement des données en JavaScript : l’évaluation paresseuse ou évaluation retardée (lazy evaluation) et l’évaluation immédiate (eager evaluation)
-
Évaluation paresseuse : L’évaluation paresseuse calcule les valeurs uniquement au moment où elles sont nécessaires. Plutôt que de générer toute la séquence d’un coup, chaque valeur est produite à la demande, ce qui économise de la mémoire et permet de traiter des séquences longues ou infinies efficacement.
-
Évaluation immédiate : À l’inverse, l’évaluation immédiate consiste à calculer toutes les valeurs d’un coup et à les stocker. C’est le cas, par exemple, lorsqu’on utilise
mapsur un tableau, où toutes les valeurs sont transformées et stockées dans un nouveau tableau. Cette méthode convient aux petites collections, mais devient inefficace pour de grands volumes de données ou des flux infinis.
Les iterator helpers en action
Pour illustrer les différents iterator helpers, prenons un exemple. Imaginons que nous disposons d’un flux de données continu qui provient de capteurs météo et qui envoie des relevés de température en temps réel. Ce flux représente des valeurs qu’on souhaite filtrer, transformer et analyser, sans devoir tout stocker en mémoire.
Pour simuler ce flux, créons un générateur temperatureStream qui produit des température aléatoire entre -20 et 50 °C :
function* temperatureStream() { const min = -20; const max = 50; while (true) { yield Math.floor(Math.random() * (max - min + 1)) + min; // Génère une température aléatoire entre -20 et 50 }}Maintenant, voyons comment chaque helper peut être utilisé pour manipuler ce flux de données.
filter(callback)
Le helper filter nous permet de ne conserver que les éléments de la séquence qui répondent à une condition. Imaginons qu’on veuille récupérer uniquement les températures au-dessus de 25 °C.
const highTemperaturesStream = temperatureStream() .filter(temperature => temperature > 25);
for (const temperature of highTemperaturesStream) { console.log(`Température élevée : ${temperature}°C`); if (Math.random() < 0.1) break; // On arrête après quelques relevés pour l'exemple}map(callback)
map est parfait pour transformer les valeurs. Supposons qu’on veuille afficher les températures en Fahrenheit plutôt qu’en Celsius.
const fahrenheitTemperaturesStream = temperatureStream() .filter(temperature => temperature > 25) .map(temperature => (temperature * 9 / 5) + 32);
for (const temperatureFahrenheit of fahrenheitTemperaturesStream) { console.log(`Température en Fahrenheit : ${temperatureFahrenheit.toFixed(2)}°F`); if (Math.random() < 0.1) break;}take(n)
Avec take, on peut limiter la séquence aux n premiers éléments, ce qui est idéal pour tester ou échantillonner un flux infini. Prenons, par exemple, les 5 premières températures élevées en Fahrenheit.
const firstFiveHighTempsFahrenheit = temperatureStream() .filter(temperature => temperature > 25) .map(temperature => (temperature * 9 / 5) + 32) .take(5);
for (const temperatureFahrenheit of firstFiveHighTempsFahrenheit) { console.log(`Température (F) : ${temperatureFahrenheit.toFixed(2)}°F`);}drop(n)
drop nous permet d’ignorer les n premiers éléments de la séquence et de commencer à analyser les relevés suivants. Imaginons qu’on veuille ignorer les trois premières lectures pour éviter des valeurs de calibrage.
const calibratedTemperaturesStream = temperatureStream() .drop(3) // Ignore les 3 premières lectures .take(5); // Prend les 5 lectures suivantes pour l'analyse
for (const temperature of calibratedTemperaturesStream) { console.log(`Lecture après calibrage : ${temperature}°C`);}reduce(callback, initialValue)
reduce est idéal pour calculer une valeur unique à partir d’une séquence, comme une moyenne ou une somme. Calculons, par exemple, la température moyenne des 10 premières lectures de températures.
const averageHighTemperature = temperatureStream() .take(10) .reduce((total, temperature, index) => { return index === 9 ? (total + temperature) / 10 : total + temperature; }, 0);
console.log(`Température moyenne : ${averageHighTemperature.toFixed(2)}°C`);forEach(callback)
Le helper forEach exécute une fonction pour chaque élément de la séquence sans rien renvoyer, ce qui le rend idéal pour effectuer des actions ou des effets de bord. Par exemple, supposons qu’on souhaite simplement afficher chaque relevé de température, sans affecter le flux.
temperatureStream() .take(5) .forEach(temperature => { console.log(`Température relevée : ${temperature}°C`); });some(callback)
some renvoie true si au moins un élément de la séquence satisfait la condition spécifiée. Par exemple, voyons si au moins une des 10 premières température est en-dessous de 0°C.
const hasFreezingTemperature = temperatureStream() .take(10) .some((temperature) => temperature < 0);
console.log(`Présence de températures négatives : ${hasFreezingTemperature}`);every(callback)
every vérifie si tous les éléments d’une séquence répondent à une condition. Par exemple, regardons si les 10 premières températures sont toutes positives.
const allTemperaturesPositive = temperatureStream() .take(10) .every(temperature => temperature >= 0);
console.log(`Toutes les températures sont positives : ${allTemperaturesPositive}`);find(callback)
find renvoie le premier élément qui répond à une condition donnée, ou undefined si aucun n’est trouvé. Trouvons la première température qui dépasse 40°C.
const firstExtremeTemperature = temperatureStream() .find(temperature => temperature > 40);
console.log(`Première température extrême : ${firstExtremeTemperature}°C`);flatMap(callback)
Le helper flatMap est idéal lorsque chaque élément de la séquence doit être transformé en plusieurs sous-éléments qui seront ensuite “aplatis” en une seule séquence continue. Cela est particulièrement utile pour éviter les structures imbriquées et simplifier la manipulation des données.
Imaginons que chaque relevé de température contient des mesures pour différentes périodes de la journée. On souhaite convertir chacune de ces températures de Celsius en Fahrenheit, puis les traiter comme une seule séquence.
function* temperatureStreamWithDailyPeriods() { while (true) { yield { morning: Math.floor(Math.random() * 30), // Température du matin en °C afternoon: Math.floor(Math.random() * 30), // Température de l'après-midi en °C evening: Math.floor(Math.random() * 30) // Température du soir en °C }; }}
const fahrenheitTemperatures = temperatureStreamWithDailyPeriods() .flatMap(({ morning, afternoon, evening }) => { // Convertit chaque relevé de Celsius en Fahrenheit return [ (morning * 9) / 5 + 32, (afternoon * 9) / 5 + 32, (evening * 9) / 5 + 32 ]; });
for (const temperature of fahrenheitTemperatures) { console.log(`Température en Fahrenheit : ${temperature.toFixed(2)}°F`); if (Math.random() < 0.1) break; // On arrête après quelques relevés pour l'exemple}toArray()
toArray convertit un itérateur en tableau, forçant ainsi l’évaluation complète de la séquence en mémoire. Cette méthode est utile pour obtenir toutes les valeurs sous forme de tableau, mais elle ne doit pas être utilisée sur des séquences infinies et doit être employée avec précaution sur de grandes séquences. Par exemple, créons un tableau contenant les 10 premières températures.
const temperatureArray = temperatureStream() .take(10) .toArray();
console.log(`Échantillon de températures :`, temperatureArray);Différence avec les méthodes de tableau
Différence avec les méthodes de tableau
Les iterator helpers, comme map, filter ou encore find, se distinguent des méthodes de tableau correspondantes par leur évaluation paresseuse. Plutôt que de traiter toutes les valeurs d’un coup, comme le font les méthodes de tableau, les iterator helpers calculent chaque valeur uniquement lorsqu’elle est nécessaire. Cela fonctionne un peu comme un “pipeline” où chaque transformation est appliquée successivement à une valeur avant de passer à la suivante.
Avec cette approche, il n’y a pas de copies intermédiaires entre chaque étape. Par exemple, lorsqu’on enchaîne map et filter, chaque transformation est appliquée successivement sur une valeur unique à chaque étape. Ce mode de traitement “à la demande” améliore les performances et réduit l’utilisation de la mémoire, ce qui est particulièrement avantageux pour les grandes collections ou les flux de données.
Utilité des iterator helpers pour le parcours de structures de données
Nous avons vu que les iterator helpers sont particulièrement utiles pour manipuler des flux de données, grâce à leur évaluation paresseuse. Mais ils sont aussi très puissants lorsqu’il s’agit de parcourir des structures de données complexes, comme les arbres, les listes chainées ou encore les graphes.
Prenons un exemple concret. Supposons que nous ayons un arbre binaire qui stocke des valeurs numériques, et nous souhaitons parcourir cet arbre pour filtrer, transformer ou agréger ses valeurs. En définissant un itérateur sur notre arbre, nous pouvons utiliser les iterator helpers pour effectuer ces opérations de manière élégante et efficace.
Voici comment nous pourrions implémenter un arbre binaire avec un itérateur en JavaScript :
class TreeNode { constructor(value, left = null, right = null) { this.value = value; this.left = left; this.right = right; }
*[Symbol.iterator]() { if (this.left) { yield* this.left; } yield this.value; if (this.right) { yield* this.right; } }}
// Construction d'un arbre binaireconst tree = new TreeNode(10, new TreeNode(5, new TreeNode(2), new TreeNode(7) ), new TreeNode(15, new TreeNode(12), new TreeNode(20) ));Dans cet exemple, nous avons défini un itérateur Symbol.iterator qui effectue un parcours en ordre infixe (in-order traversal). Pour utiliser les iterator helpers sur notre arbre, nous pouvons créer un itérateur à partir de celui-ci en utilisant Iterator.from. L’utilisation de Iterator.from est nécessaire ici car les iterator helpers (filter, map, reduce, etc.) font partie des nouvelles méthodes d’itération en JavaScript et ne sont disponibles que sur les instances d’un objet Iterator. Les structures de données comme les tableaux ou les objets que nous créons, comme ici, peuvent implémenter le protocole d’itération en utilisant Symbol.iterator, mais cela ne leur donne pas automatiquement accès aux helpers.
Bref, voyons quelques exemples d’utilisation.
Filtrer les valeurs supérieures à 10
Nous voulons extraire toutes les valeurs de l’arbre qui sont strictement supérieures à 10. En utilisant l’iterator helper filter, nous pouvons parcourir l’arbre en appliquant ce critère à chaque valeur, et stocker le résultat dans un tableau.
const highValues = Iterator.from(tree) .filter(value => value > 10) .toArray();
console.log(highValues); // [12, 15, 20]Calculer la somme des valeurs
Imaginons maintenant que nous voulons calculer la somme de toutes les valeurs de l’arbre. Le helper reduce est parfait pour cela. Il accumule les valeurs en appliquant une fonction d’agrégation.
const sum = Iterator.from(tree) .reduce((acc, value) => acc + value, 0);
console.log(sum); // 71Vérifier si toutes les valeurs sont positives
Enfin, vérifions si toutes les valeurs de l’arbre sont positives. Pour cela, nous utilisons le helper every, qui renvoie true si chaque valeur satisfait le prédicat, et false dans le cas contraire.
const allPositive = Iterator.from(tree) .every(value => value > 0);
console.log(allPositive); // trueCes exemples illustrent la puissance des iterator helpers lorsqu’ils sont combinés à des structures de données personnalisées, comme notre arbre binaire.
Pour finir…
Nous avons exploré les iterator helpers et les nombreuses possibilités qu’ils apportent en JavaScript. Ces nouveaux outils enrichissent le langage en offrant des méthodes performantes pour manipuler les séquences de données de façon élégante et efficace. Grâce à l’évaluation paresseuse (lazy evaluation), on peut enchaîner les transformations sans créer de copies intermédiaires en mémoire, ce qui est particulièrement précieux pour les applications exigeantes en ressources ou le traitement de grandes quantités de données à la demande.
Il est également intéressant de noter que les streams dans Node.js peuvent être manipulés comme des itérateurs asynchrones. Cela signifie que vous pouvez utiliser des constructions telles que for await...of pour consommer des streams de manière plus intuitive et efficace. Sachez également que les iterator helpers sont disponibles, bien qu’encore au stade expérimental au moment de la rédaction de cet article, pour les streams dans Node.js. Mais ça mérite peut-être un autre article sur les streams Node.js.
On arrive donc à la fin de cet article, et c’était un vrai plaisir de replonger dans l’écriture d’un article sur JavaScript après tout ce temps. N’hésitez pas à le partager avec vos collègues, ami(e)s, ou toute personne qui pourrait trouver ces informations utiles. Merci !



Partage ta réflexion, pose une question ou laisse un retour.